Character encoding basic
Another character encoding post?
Yes, there are so many good posts already out there - listed in reference section below - about character encoding. I realize, however, that all those posts assume some prior basic understanding.
In this post, I will try to explain it in very simple terms to make it easy to understand for anyone with no prior knowledge of character encoding.
Also, if you can’t still explain precisely why 1 character != 1 byte of memory, then this post is for you.
The only things that you need to know are:
"Computers don’t understand words or numbers the way humans do. They are programmed to store in binary (0 and 1) format.", read more.- At the smallest scale on the computer, information is stored as bits and bytes;
1 byte = collection of 8 bits. Byte is the smallest addressable unit of memory in many computer architectures.
Let’s get started.
Definition
Encoding is simply the process of transforming information from one format into another. In simple terms, encoding is the way characters are stored into memory.
Encoding is basically a process of converting human-readable format to computer understandable format. Since computers only recognize binary data, characters must be represented in binary format.
Example
The below image represent the English alphabets mapping to a sequential number
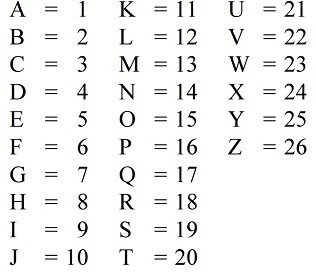
Here, the English alphabets represent a set of English characters and each character is mapped to a decimal number.
Imaging this mapping is stored somewhere (code page is the technical term used for these mappings) in computer and when computer encounters a letter C, it will find it corresponding mapping number, 3 in this case. To be able to that in memory, computer will convert 3 to a binary format 11 and it will be stored in computer memory as 000000011 - the smallest addressable/storage unit is Byte (8 bits).
Terminology
Before we jump into character encoding, it’s important to understand the common terms used; listed in the table below. The examples in the table are based on the above example of the English alphabets.
| Term | Example |
|---|---|
| Character: A character is a minimal unit of text that has semantic value. |
C (Latin C) |
| Character set: A character set is a collection of characters that might be used by multiple languages. |
A to Z |
| Coded character set: A coded character set is a character set in which each character corresponds to a unique number. |
A to Z mapped to 1 to 26 |
| Code point: A code point of a coded character set is any allowed value in the character set or code space. |
3 for letter C |
| Code space: A code space is a range of integers whose values are code points. |
1 to 26 |
| Code unit: A code unit is a bit sequence used to encode each character of a repertoire within a given encoding form. It can be considered as the granularity level. |
8 bitsC -> 3 -> 11 -> 00000011 |
Concepts
ASCII
Before learning the current standard encoding concepts, we need to understand a little about ASCII (American Standard Code for Information Interchange).
It is a character set containing 128 characters encoded using 7-bits. Refer the table below:
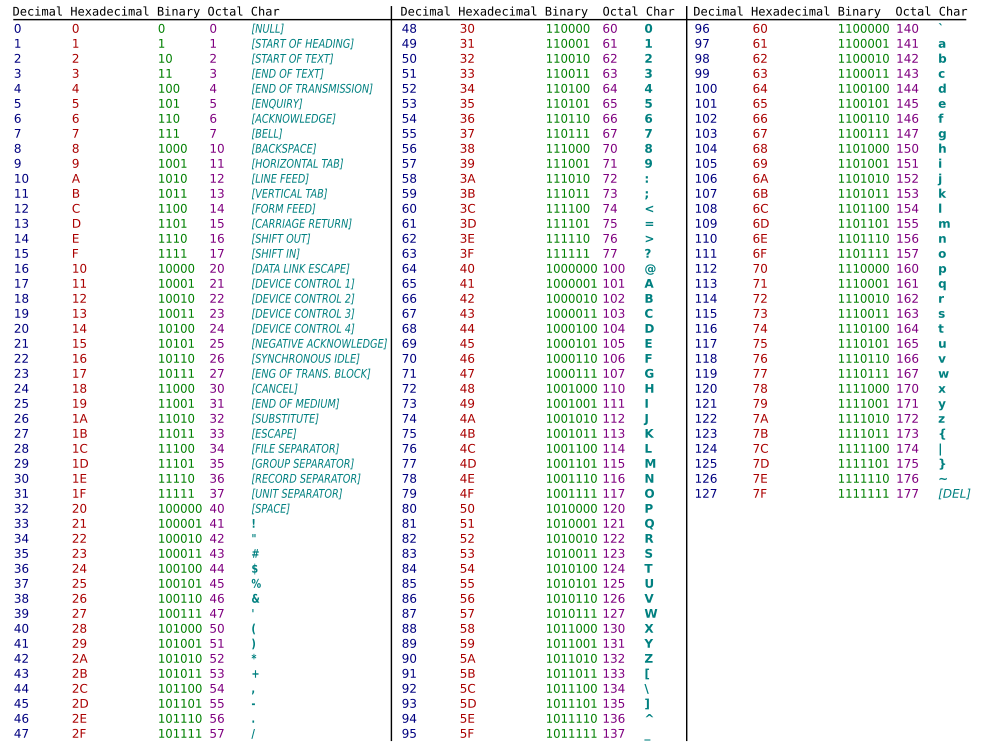
Each character has a direct representation on a computer - stored in a fixed number of bits. For example: A -> 41 -> 100 0001 -> 0100 0001 (stored as 8 bits/1 byte).
The problem with encoding that map directly representation to storage is; they don’t scale well. 8 bits can only handle 256 characters, not complete but good for English, and when you consider other languages then it becomes unmanageable and unusable.
Character set and encoding are used interchangeably for ASCII - historical reason. Please remember ASCII is an encoding.
Unicode
Unicode is an information technology standard for the consistent encoding, representation, and handling of text expressed in most of the world’s writing systems. The standard is maintained by the Unicode Consortium.
In Unicode, a letter maps to an entity (code point) which is still just a theoretical concept. It can be represented in memory or on disk multiple ways.
Every letter in every alphabet is assigned a number by the Unicode consortium which is written like this: U+0639. This
number is called a code point. The U+ means “Unicode” and the numbers are hexadecimal.
For example, Hello string, in Unicode, corresponds to these five code points:
U+0048 U+0065 U+006C U+006C U+006F
Encoding
Above, we have just explained the mappings - a theoretical concept, how do we store/converts these code points to actual bytes and bits on a computer?
That’s where encoding comes in.
To keep things simple, I will explain encoding with examples of UTF-8 only.
Unicode provides various ways of converting the code points to actual bits, these are known as Unicode Transformation Formats (UTFs) - UTF-8, UTF-16, UTF-32 etc. The table below summarizes the properties of UTFs.
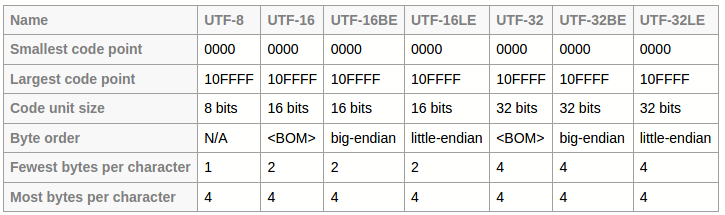
https://unicode.org/faq/utf_bom.html
UTF-8
UTF-8 is a variable-width character encoding capable of encoding valid character code points in Unicode using one to four one-byte (8-bit) code units.
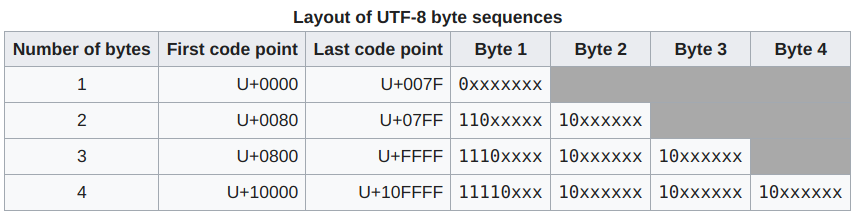
https://en.wikipedia.org/wiki/UTF-8
As you can see from the above table, every code point from 0-127 (U+0000 - U+007F) is stored in a single byte. This makes UTF-8 backward compatible with ASCII. For example, Hello, Unicode U+0048 U+0065 U+006C U+006C U+006F, is stored as 48 65 6C 6C 6F, which is same as ASCII.
Backwards compatibility with ASCII and the enormous amount of software designed to process ASCII-encoded text was the main driving force behind the design of UTF-8.
Please note that 8 in UTF-8 does not mean that each code point uses only 8 bits. It represents the code unit size (refer terminology section). Refer a few examples below for better understanding:
Example
Referenced from https://en.wikipedia.org/wiki/Character_encoding#Terminology:
Consider a string of the letters “abc” followed by U+10400 𐐀 DESERET CAPITAL LETTER LONG I (represented with 1 char32_t, 2 char16_t or 4 char8_t). That string contains:
-
four characters;
-
four code points
-
either:
- four code units in UTF-32 (00000061, 00000062, 00000063, 00010400)
- five code units in UTF-16 (0061, 0062, 0063, d801, dc00), or
- seven code units in UTF-8 (61, 62, 63, f0, 90, 90, 80).
Below detailed commands will represent the above string to actual mapping to bits on computer. For better understanding, we have created two files: unicode.txt containing 𐐀 and ascii.txt containing abc.
The below commands (executed on Linux operating system, you may need to install the utility) list the content of two files and also, list the corresponding hex and binary form of the text:
# Unicode text
$ cat unicode.txt
𐐀
## hex form
$ xxd -g 1 unicode.txt
00000000: f0 90 90 80 0a .....
## `f0 90 90 80` is the hex form of 𐐀 and 0a is for the line feed
## binary form
$ xxd -b unicode.txt
00000000: 11110000 10010000 10010000 10000000 00001010 .....
# ASCII text
$ cat ascii.txt
abc
## hex form
$ xxd -g 1 ascii.txt
00000000: 61 62 63 0a abc.
## `61 62 63` is the hex form of abc and 0a is for the line feed
## binary form
$ xxd -b ascii.txt
00000000: 01100001 01100010 01100011 00001010 abc.
Conclusion
Please keep in mind that UTF-8/16/32 are encoding. Unicode is a character set.
I hope this has been useful, and if you have questions, comments, suggestions, or if anything is not clear or not easy to understand then please let me know. You can contact me directly through email.